
How to Build a Proprietary Data Moat in AI (7 Practical Moves)
What a data moat really is — and 7 practical moves to turn proprietary data into a durable competitive advantage in AI.


In short: A data moat is a competitive advantage that comes not from how much data you own, but from how fast that data makes your AI system improve. In the AI era, accumulation alone is worthless — data becomes a moat only when it creates a learning loop competitors can't easily replicate. This guide breaks down seven practical moves for building a proprietary data moat, from capturing unique usage data to engineering compounding feedback loops.
Most companies think data becomes a competitive moat just by accumulating it.
They’re wrong.
In the AI era, data only becomes a moat if it improves how your system learns faster than competitors can replicate.
In this guide, you’ll learn how to build a proprietary data moat by designing feedback loops, not data pipelines, and why most data strategies quietly fail.
What Is AI Data Strategy?
AI data strategy is the operating approach that determines how an organization collects, governs, and activates data so AI systems can learn faster, improve decisions, and compound advantage over time.
What Is a Proprietary Data Moat?
A proprietary data moat is a defensible advantage created when a system generates unique interaction and feedback data that competitors cannot easily reproduce because it is tied to how the product learns.
How to Build a Data Moat (Quick Answer)
A proprietary data moat is built when your system:
generates unique interaction data, not just logs
captures feedback that improves decisions
reinforces learning faster than competitors can copy
embeds that learning into product performance
In practice, this means designing feedback loops, not just storing data.
Examples include OpenAI’s feedback loops, TikTok’s behavioral signals, and Stripe’s transaction learning systems.
TL;DR — How Data Becomes a Competitive Moat
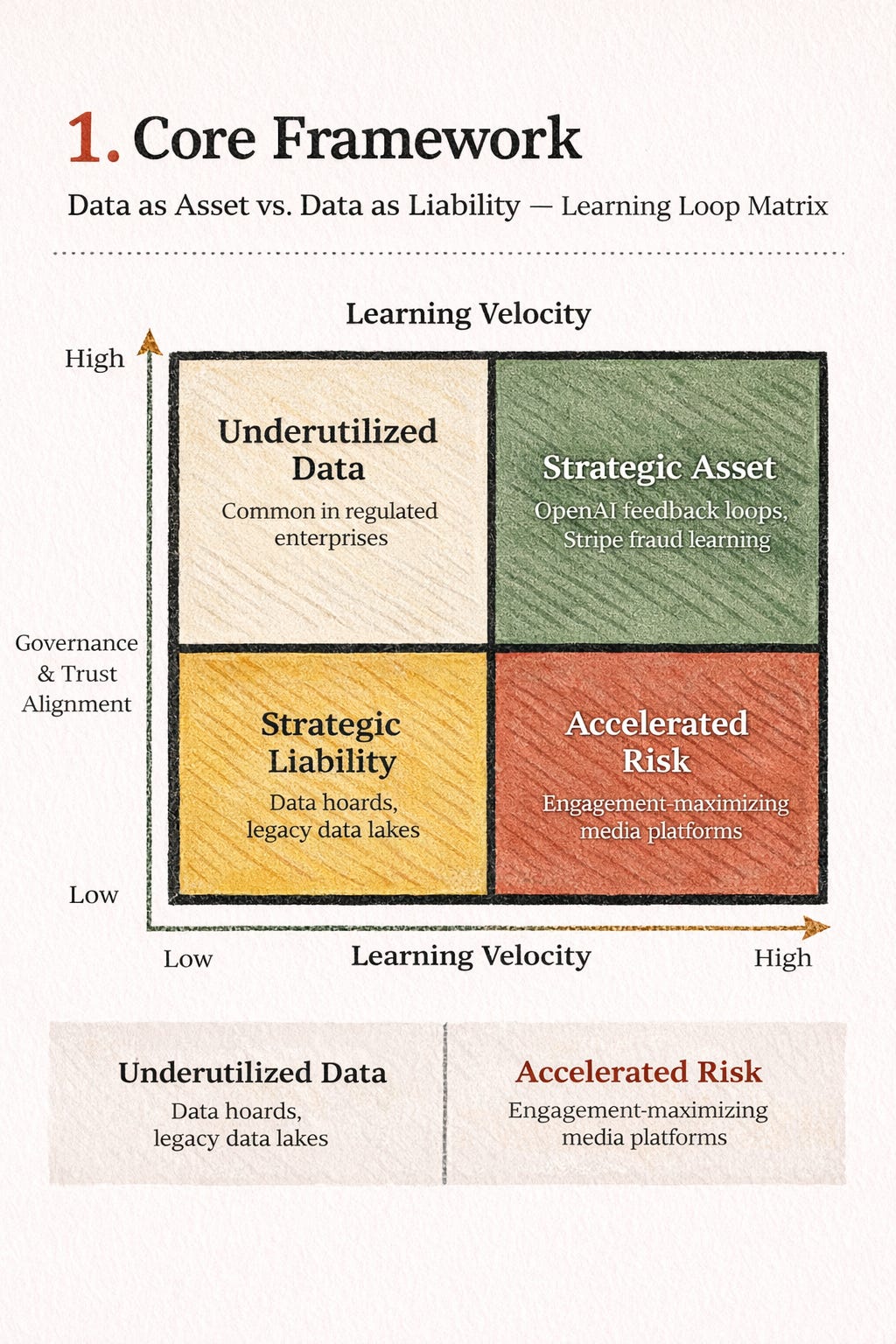
Data becomes a strategic asset when it improves system intelligence over time in ways competitors cannot easily replicate. It becomes a liability when it accumulates without learning, increases complexity faster than insight, or exposes the organization to governance and trust risks without offsetting advantage.
In the AI era, advantage does not come from having data.
It comes from turning data into intelligence faster than rivals can copy.
Short answer: Data becomes a moat when it improves decision quality through learning loops that competitors can’t replicate.
How to Build a Proprietary Data Moat (7 Practical Moves)
Instrument feedback loops, not just event logging
Capture correction data from users and operators
Prioritize interaction data over exhaust data
Design incentives that improve signal quality
Close learning loops weekly, not quarterly
Build governance into the architecture from day one
Turn insights into data products teams can actually use
Table of Contents
Why “More Data” Is the Wrong Strategic Question
Not All Data Creates Advantage
Proprietary Data Moats Are Behavioral, Not Volumetric
Case Examples — When Data Becomes Leverage (and When It Doesn’t)
When Data Quietly Turns into a Liability
A Strategic Test for Data Leverage
Designing Data for Learning, Not Storage
Closing Thought — From Data Accumulation to Intelligence Compounding
Most data moats fail because companies collect data but never turn it into feedback that improves the product. A real data moat is not a database. It is a learning system.
1. Why “More Data” Is the Wrong Strategic Question
For much of the digital era, data strategy followed a simple arc: more users produced more data, more data improved models or analytics, and better outputs attracted more users. That logic worked when data was scarce, feedback cycles were slow, and intelligence was largely human-mediated.
AI breaks this model.
Data is no longer scarce. Signal is.
What matters now is whether data contributes to learning loops that actually improve system performance. Organizations that continue to optimize for accumulation instead of learning often discover that scale increases cost and risk faster than insight.
The strategic question in 2026 is no longer how much data you have.
It is what your system is able to learn from that data — and how quickly.
2. Not All Data Creates Advantage
One of the most common strategic errors is treating all data as equally valuable. In practice, most organizations sit on layered mixes of data types, only some of which meaningfully contribute to competitive advantage.
Data types (from weakest → strongest moat):
Exhaust data (logs, telemetry)
Operational data (transactions)
Interactional data (choices + behavior)
Learning data (feedback + corrections)
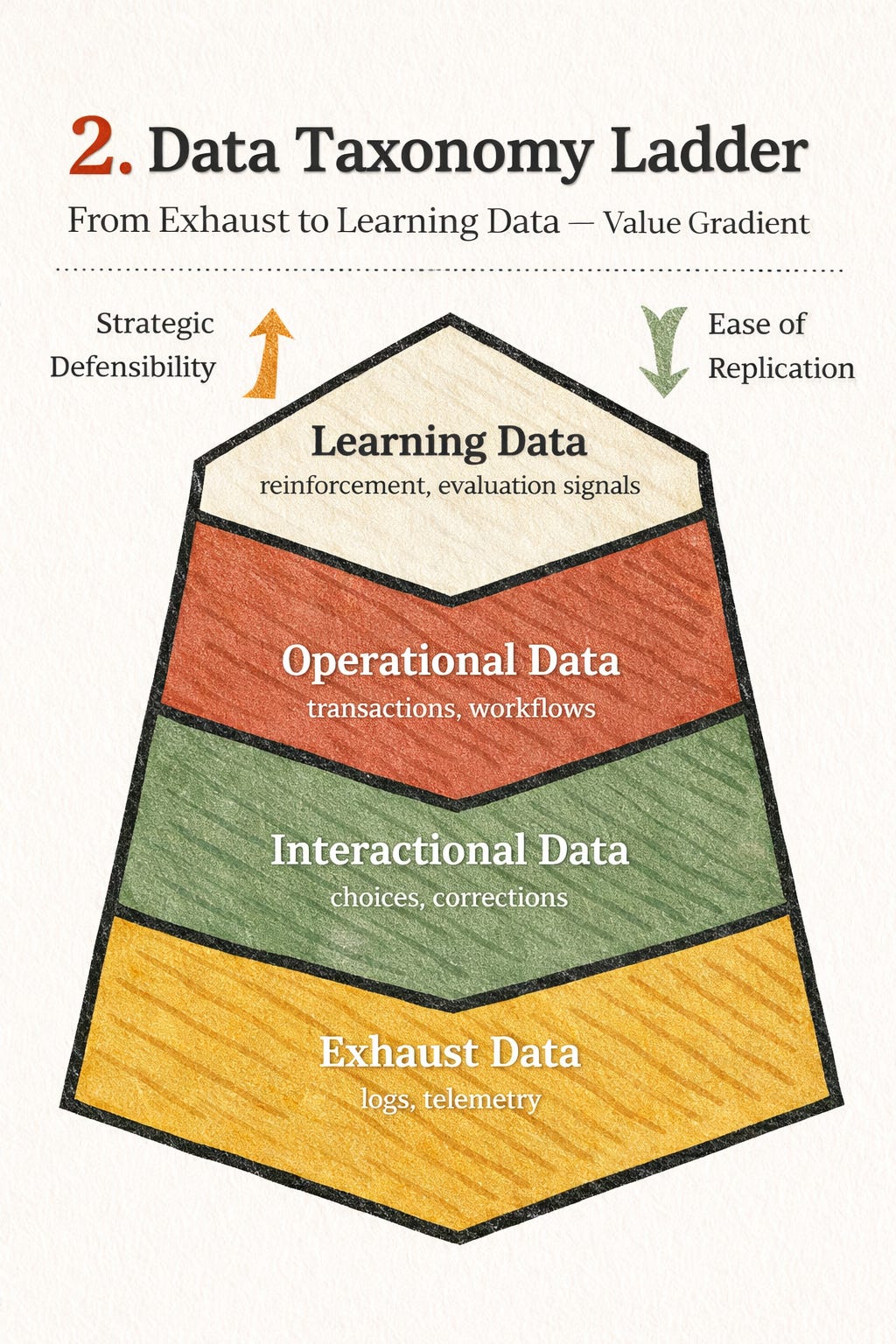
At the lowest level sits exhaust data: logs, telemetry, raw activity traces. This data is easy to generate and useful for monitoring, but it rarely differentiates one system from another.
Operational data sits a step above, capturing transactions, workflows, and real economic activity. While more valuable, it is often structurally similar across competitors.
True advantage begins when data is generated through interaction rather than observation.
Interactional data captures how users engage with a system — their choices, corrections, preferences, and tradeoffs. This data is deeply shaped by interface design, incentives, and context. It cannot be easily scraped, licensed, or reproduced because it is inseparable from the system that produced it.
Rarest of all is learning data: information explicitly captured to improve future decisions. This includes reinforcement signals, evaluation feedback, and human-in-the-loop corrections. Learning data does not emerge accidentally. It exists only when systems are deliberately designed to capture it.
This is why the most defensible data advantages are not stockpiles.
They are feedback architectures.
3. Why Most Data Moats Fail
A persistent misconception in strategy circles is that data cannot be a moat because competitors can always acquire similar datasets.
This misses the point.
What competitors cannot easily replicate is the behavior that generated the data in the first place. When users behave differently because of how a system is designed — how it routes tasks, requests feedback, or resolves uncertainty — the resulting data carries context that cannot be separated from the system itself.
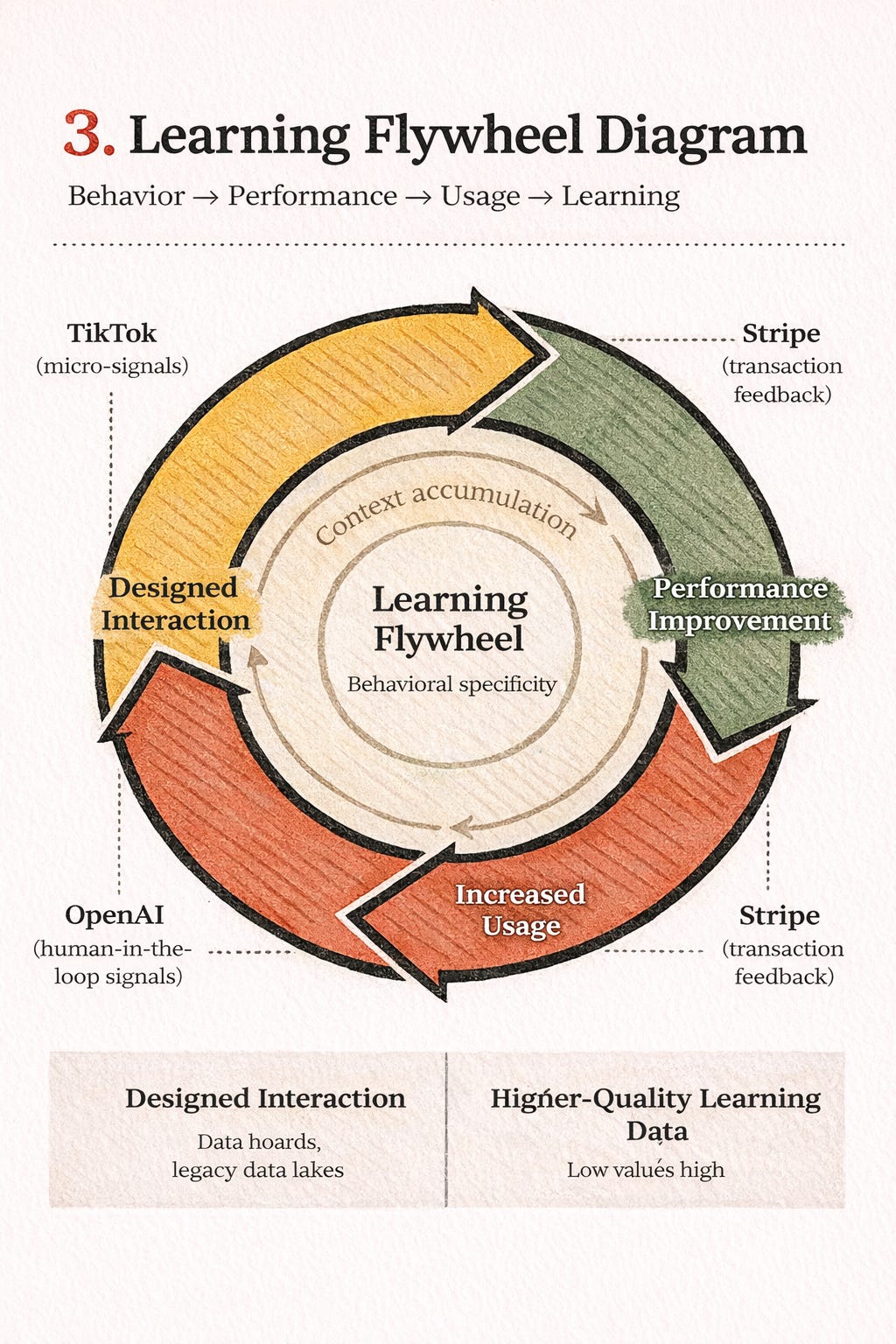
Modern data moats emerge when interaction improves performance, performance attracts more usage, and usage deepens learning. At that point, data advantage is no longer a static resource.
It becomes a self-reinforcing loop embedded in the system’s operation.
This is why, in 2026, the strongest data moats look less like databases and more like learning flywheels.

What follows is where data strategy stops being theoretical and starts becoming operational.
4. Case Examples — When Data Becomes Leverage (and When It Doesn’t)
Strategy becomes real when systems behave differently under pressure. The difference between data as an asset and data as a liability is easiest to see in how leading platforms design — or fail to design — learning into their core loops.
OpenAI — Interactional Data as a Learning Engine
OpenAI’s advantage does not come from uniquely large datasets. Much of the raw text used to train language models is broadly accessible. What differentiates OpenAI is how interaction generates learning continuously.
Every prompt, correction, rating, refusal, and tool invocation produces structured feedback about intent, failure modes, edge cases, and trust boundaries. This data is not passive exhaust. It is routed deliberately into evaluation pipelines, reinforcement tuning, safety calibration, and routing optimization.
The result is not just better models, but faster learning velocity. Competitors can approximate the models. What is far harder to replicate is the behavioral loop: millions of users interacting in ways that continuously sharpen inference under real-world conditions.
Here, data compounds because it is inseparable from the system that generates it.
TikTok — When Behavior Trains the System
TikTok is often described as a content platform. In reality, it is a behavior-sensing machine.
Users do not explicitly tell TikTok what they want. They reveal it through micro-signals: watch time, rewinds, hesitations, skips, swipe velocity. The platform is designed to capture these signals with extreme fidelity and feed them directly into ranking and recommendation loops.
This interactional data is extraordinarily difficult to replicate outside TikTok’s environment. Copying the content does not copy the learning.
TikTok’s data advantage is not volume.
It is resolution and speed.
If you’re trying to connect these pieces into something durable, this is the missing layer: agentic strategy →
